ГлавнаяИсследованияИспользование ML/Data Open Source в России
Университет ИТМОИспользование ML/Data Open Source в России

Топ российских разработчиков, которые занимаются созданием своих открытых решений или участвуют в других разработках Open Source (в сфере Data/ML)
Сотрудники центра «Сильный ИИ в промышленности» ИТМО изучили применение программного обеспечения с открытым исходным кодом (Open Source) в областях искусственного интеллекта (ИИ), машинного обучения (ML) и Data Science.
В основу исследования легли количественные метрики и интервью с экспертами из компаний «Яндекс», «Сбер», Т-Банк, VK, Wildberries, Rocket Control, CodeScoring, а также МФТИ. Кроме того, документ содержит прогноз по развитию ИИ на ближайшие два года и обзор используемых решений в различных категориях. Вторая часть исследования основана на автоматизированном анализе открытых репозиториев с кодом, ссылок на них, информации о пользователях, участвовавших в работе на проектах.
Авторы исследования разделили решения Open Source на несколько категорий: инструменты ML и AutoML (CatBoost, LightAutoML, FEDOT, LightGBM, AutoGluon и др.), математическое обеспечение (numpy, kmath, nntile, YaFSDP, RAPIDS), инфраструктура (Platform V, YTsaurus, Hadoop, Spark), визуализация и BI (pandas, polars, metabase, SHAP, Superset, Datalens и др.), хранение данных (PostgreSQL, Tarantool, ClickHouse, YDB, Data Detective, MongoDB), MLOps и LLMO (LangChain, llmware, GigaChain).
Ключевые выводы:
- в топ-10 российских разработчиков собственных открытых решений и участников других разработок Open Source (в сфере Data/ML) по результатам опроса экспертов и анализа открытых данных вошли «Яндекс», «Сбер», Т-Банк, Postgres Pro, VK, Avito, Evrone, МТС, Selectel, университеты и институты;
- ключевыми игроками Open Source в России среди академической среды названы ИТМО, «Сколтех», НИУ ВШЭ и AIRI;
- сохраняется международность Open Source (как в России, так и во всем мире), обусловленная связностью внутри сообщества и «эффектом масштаба»: чем больше у проекта потенциальных пользователей, тем выше его шанс на успешное развитие. Но создаются и региональные площадки и платформы;
- открытые инструменты востребованы в технологическом стеке и крупных компаний, и частных пользователей. Их авторы — как большой технологический бизнес, так и небольшие команды, в том числе академические;
- Open Source в сфере ИИ не ограничивается кодом. Публикации моделей, данных и бенчмарков тоже важны. Многие активно используемые датасеты создаются российскими компаниями;
- почти все используемые в России инструменты ML — это решения Open Source. Среди них авторы выделяют реализацию конкретных моделей машинного обучения (например, Scikit Learn) или фреймворки для «сборки» своих моделей (например, PyTorch и TensorFlow в случае нейронных сетей). AutoML-решения применяют не так широко, но про сами инструменты (например, проект LightAutoML) многие знают;
- опрошенные эксперты назвали в числе проблем противоречия в требованиях к реализации у создателей и пользователей открытых инструментов, а также качество документации, поддержку и совместимость Open Source с корпоративными системами и платформами;
- в России растет число участников движения Open Source, в том числе интегрированного в общемировое сообщество через развитие многих открытых проектов. При этом все держится на энтузиастах. Сотрудникам компаний трудно продвигать идеи выноса части корпоративного кода в Open Source, обосновывать финансирование этого направления и его пользу для имиджа компании;
- для развития и популяризации новых проектов недостаточно мероприятий, программ поддержки, грантов, каналов для привлечения пользователей и участников;
- эксперты отмечают, что контрибьюторам часто не хватает сочетания «предметных» компетенций и навыков разработки ПО. Наблюдается и нехватка опыта в разработке у специалистов в ML и Data Science;
- эксперты возлагают надежды на мультиагентные подходы на основе больших языковых моделей (LLM), вплоть до замены части команды разработки на ИИ-агентов. При этом общая постановка задач остается человеку. С практической точки зрения это означает рост запроса на инструменты из сферы LLMOps и AutoML. Несмотря на то что существует множество активно используемых проектов, многие ниши остаются незакрытыми;
- есть запрос на демократизацию и автоматизацию применения ИИ-решений, в том числе на упрощение «погружения» в новые проекты (как в роли пользователя, так и в роли разработчика), автогенерацию кода для связывания библиотек и фреймворков между собой, облегчение работы с документацией (для пользователей) и ее генерации (для разработчиков), а также интерпретацию и объяснение результатов работы ИИ.
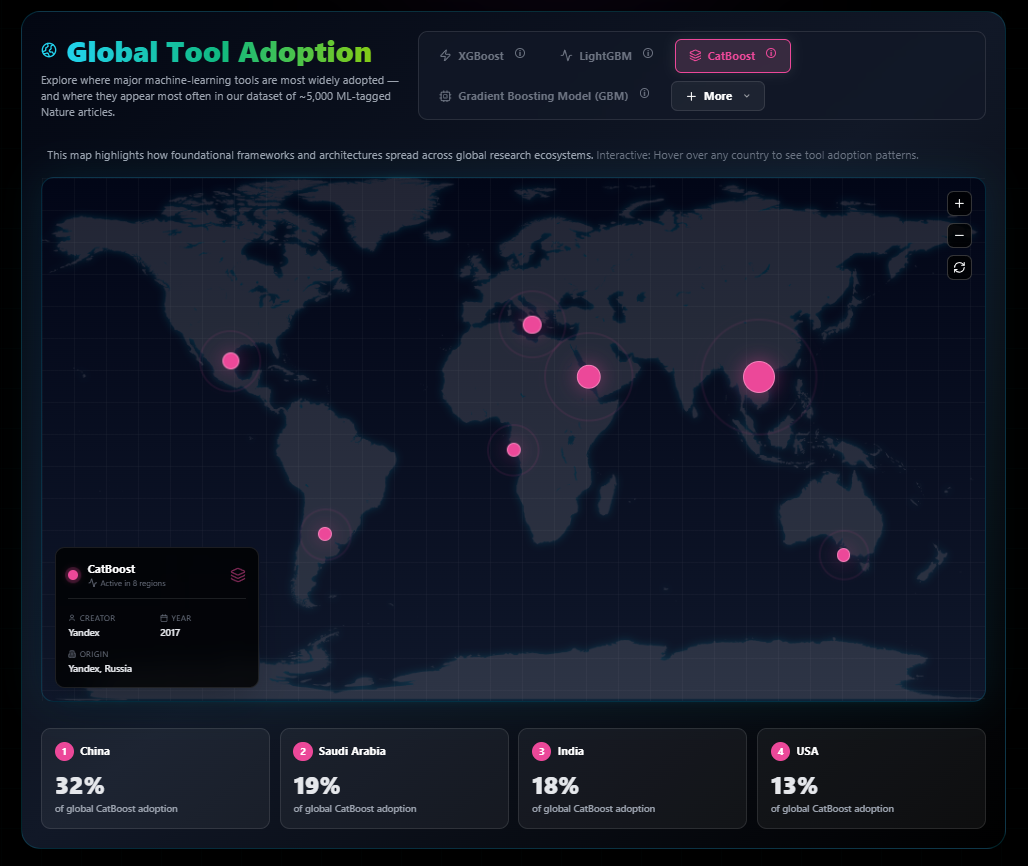 MarkTechPost
MarkTechPostML Global Impact Report 2025
Алгоритм «Яндекса» CatBoost стал одним из наиболее часто упоминаемых ML-инструментов в научных статьях.Подробнее
 Capgemini
CapgeminiTurbocharging Software with Gen AI
В 2026 году до 85% разработчиков ПО могут начать использовать генеративный ИИ.Подробнее PwC
PwC2026 AI Business Predictions
Аналитики прогнозируют в 2026 году увеличение значимости ИИ-агентов в бизнесе, развитие систем оркестрации.Подробнее Технологии Доверия
Технологии ДоверияОценка ИИ российским бизнесом
В России 86% компаний внедряют ИИ-инструменты.Подробнее
Нажимая на кнопку, вы соглашаетесь с политикой конфиденциальности
ICT.Moscow — открытая площадка о цифровых технологиях в Москве. Мы создаем наиболее полную картину развития рынка технологий в городе и за его пределами, помогаем бизнесу следить за главными трендами, не упускать возможности и находить новых партнеров.